
经典论文阅读---LSTM
记录下LSTM
本文解决了什么问题
在摘要中提到了,传统的BPTT或RTRL会出现,误差(就是梯度)消失、爆炸的问题;梯度消失会导致更新过慢,甚至不能学习,梯度爆炸会导致权重震荡
RNN和Lstm的不同之处,在于改进了RNN的梯度爆炸、消失问题
本文利用lstm的结构,改进了这个问题,整个结构使得恒定的error flow,不会梯度爆炸、消失(感觉是吹的)
BPTT
BPTT是back propagation throught time,是梯度沿时间通道传播的算法
假设在时间$t$,真实值(文中说的target)是$d_{k}(t)$,$k$指第$k$个值;预测值为$y^{k}$
有一说一,原论文的公式写得太简洁了
如果损失函数是mse,即
loss = \sum_t \sum_k \left( d_k(t) - y^k(t) \right)^2
那么第$k$的单元的误差就是,对第$k$个神经元求导,即$\frac{\partial \text{loss}}{\partial net_k(t)} = \vartheta_{k}(t)$
文中把这个叫做$k’s$ error ...
经典论文阅读---RNN
没想到这篇文章时代如此久远,是Rumelhart David E、Hinton Geoffrey E、Williams Ronald J 三位大神在1985年发表的
年代久远,以至于没有数字版本的pdf。。。
阅读这篇文章,了解最开始的RNN的想法
这篇文章不知道有几个版本,我找到的每篇都不太一样。。
http://www.cs.utoronto.ca/,这份pdf只有四页,这篇文章的题目是Learning representations by back-propagating errors
stanford的版本,足足23页;这篇文章的题目是learning internal representations by error propagation
这两个不一样,本文主要讲第一个文章
首先文章描述了一种新的学习过程,反向传播;这种学习过程是神经元的学习过程
这个过程,就是重复的调整权重,来最小化网络输出值和真实值之间的差距
由于权重的不过调整,所以中间的隐藏单元就可以来表示重要的特征
文章在第一段就提到,如果不加隐藏神经元,那么,输入和输出是直接相连的,所以上面提到的调整权 ...
经典论文阅读---word2vec
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
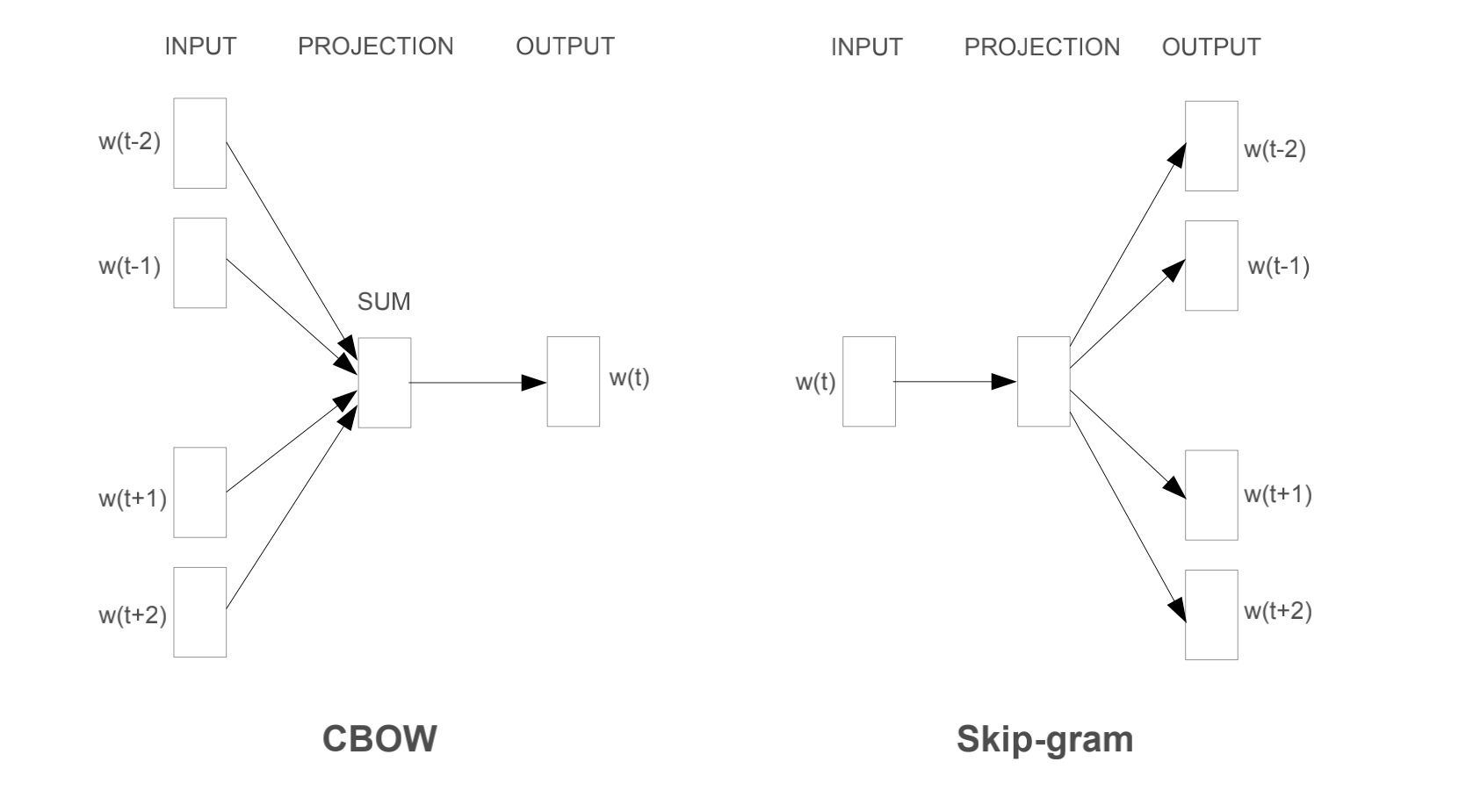
第一篇文章在NNLM的基础上做了修改,提出了CBOW和skip-gram模型
第二篇文章暂时还没看,大概是讲skip-gram的
这里感谢知乎的回答,大部分博客都只讲原理,不讲输入输出流,其实这对模型的理解不够
知乎cbow 与 skip-gram的比较讲得比较好
参考github博客和知乎,CSDN
介绍
首先提出了以往的NLP,大多将words视为原子级别的单位,不可再分;没有词之间的相关性这种概念。选择这种模型的好处是,简单、稳定、简单模型在大量数据训练的效果好优于复杂模型在小数据集上的效果。很有名的模型就是n-gram
本文的目的是,学习高质量的word vectors,也就是词向量、NNLM中的feature vector
在这篇文章之前,没有人可以在hundred of miilions of w ...
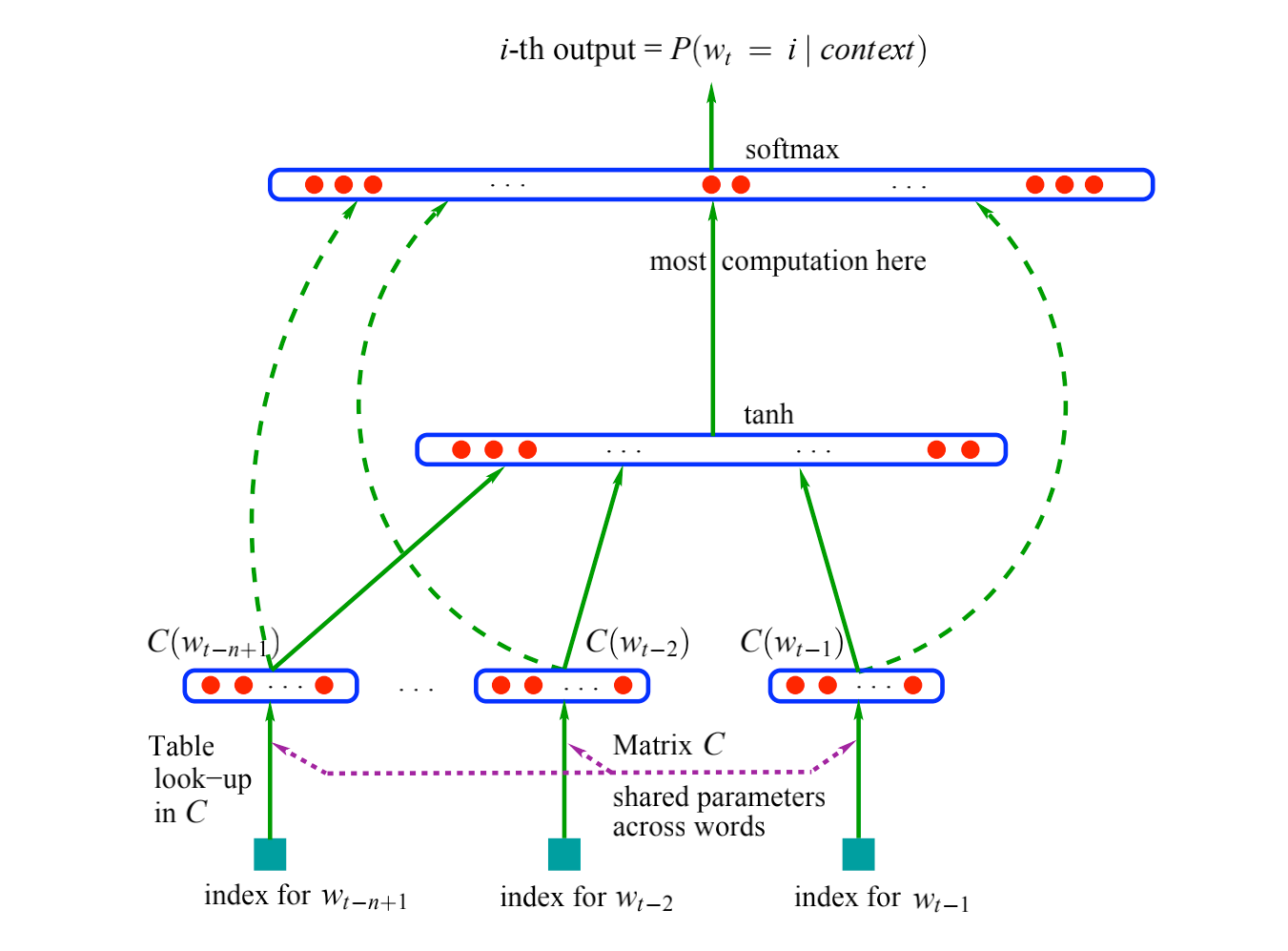
经典论文阅读---NNLM
NNLM,是非常经典的NLP论文,这是第一篇将神经网络引入nlp的论文,应该反复咀嚼文中的思想
下面以翻译的形式慢慢解读
介绍123456A fundamental problem that makes language modeling and other learning problems difficult is thecurse of dimensionality. It is particularly obvious in the case when one wants to model the jointdistribution between many discrete random variables (such as words in a sentence, or discrete attributes in a data-mining task).
上面提到了对语言模型建模的困难:维数灾难
文中给出的例子是:假设我们的字典有10万个词语,现在需要对10个词语进行建模,那么这10个词语的概率就是$100000^{10}-1=10^{50} - 1$个参数
10 ...
wenet训练笔记
1234567# 这两个是配置环境,在path.sh下修改 /KALDI_ROOT的地址. ./path.sh || exit 1;. ./cmd.sh || exit 1;nj=16feat_dir=fbankdict=data/dict/lang_char.txt # 字典位置
step -1
这一步是下载数据
123# data是数据存放地址,自己下载了的话,就修改位置data=/export/data/asr-data/OpenSLR/33/data_url=www.openslr.org/resources/33
step 0
这个是数据准备,在wenet的s0里面只调用了local/aishell_data_prep.sh,在s1里面还用了kaldi
123456789101112# aishell_data_prep.sh# 输入两个地址, ${data}/da ...

transformer-xl
transformer-xl
记录下学习transformer-xl的内容
这篇文章主要是在原来的transformer的基础上改进了长度列
整个模型的改动就在下面的公式了
\begin{aligned}
\widetilde{\mathbf{h}}_{\tau}^{n-1}=&\left[\mathrm{SG}\left(\mathbf{m}_{\tau}^{n-1}\right) \circ \mathbf{h}_{\tau}^{n-1}\right] \\
\mathbf{q}_{\tau}^{n}, \mathbf{k}_{\tau}^{n}, \mathbf{v}_{\tau}^{n}=& \mathbf{h}_{\tau}^{n-1} \mathbf{W}_{q}^{n \top}, \widetilde{\mathbf{h}}_{\tau}^{n-1} \mathbf{W}_{k, E}^{n} \top, \widetilde{\mathbf{h}}_{\tau}^{n-1} \mathbf{W}_{v}^{n \top} \\
\mathbf{A}_{\tau, ...
tokenizer
记录下分词器是怎么做的
主要参考来源tokenizer_summary和其他的做法
一、transformers里面的分词器
transformers里面有BertTokenizer,GPT-2,RoBERTa,,XLM
文章中提到多种字典的相似度
bert分词器的实验
二、如何将句子分成一个个token1、基于空格分词
最简单的方法,使用空格分词,bert的pretokenizer就是这么做的
123"Don't you love 🤗 Transformers? We sure do.".split(" ")# 结果["Don't", 'you', 'love', '🤗', 'Transformers?', 'We', 'sure', 'do.']
上面的做法有一点不好,没有考虑词根的问题,如Transformers?与Transformer是一样 ...
loss优化
这篇是我在看完bert预训练之后,bert的两个任务的loss直接加起来,之后去学习怎么调整loss
这里参考了天池比赛给出的loss调整方法:
第一篇是Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
第二篇是Dynamic task prioritization for multitask learning
第三篇是End-to-End Multi-Task Learning with Attention
第一篇
这篇文章是cv里面的,但是它讲了两种loss的组合方式,第一种是连续性的output(如输出某个物体的距离,文章中的depth regression),第二种是分类的output(如语义分割,每个像素点是不是边界)
假设我们的模型输出值是$\mathbf{f}^{\mathbf{W}}(\mathbf{x})$,这里的$\mathbf{x}$是模型的输入值,如[batch_size, seq_len, hidden_size]这种,$\mat ...

bert
由于已经了解了transformer了
这篇博客记录下bert是怎么做预训练、fine tune,并以源码形式的展示
源码网址
数据的清洗
数据的清洗代表了,训练的方法
样本数据一共有三篇短文(以空行分隔),每一行为一个自然句子,下面展示两篇短文
读取文章,并转成unicode的形式
将句子分词,就是tokenize
取一篇文章,我们允许的句子最大长度是max_seq_length=128,但每个句子会加上[CLS] [SEP] [SEP],所以从文章的句子中抽取的句子长度是max_num_tokens=128-125,所以我们目标取出的target_seq_length=max_num_tokens=125
注意,通常希望把序列的长度填充到最大长度,所以短的句子浪费计算消耗,但有时候(大概10%的时候)希望采用短句来最小化预训练和微调的差异,所以源码中有short_seq_prob=0.1,以这个概率生成短句子,就是target_seq_length=[2, ..., 125]
源码中维护了一个chunk,用了不断的添加句子进去,直到这个chunk的token数量超过t ...

dropout
这篇文章记录下dropout的原文阅读,以及它提出来的想法
原文是Dropout: A Simple Way to Prevent Neural Networks from Overfitting
什么是dropout
在神经网络中,很容易过拟合,dropout的第一个想法就是希望可以缓解过拟合
dropout的核心思想就是以概率$p$随机保留网络中的一个单元
如下图,左边一个全连接的前馈神经网络
右边是随机去掉一些单元后,一个子网络,也叫thinned networks
为什么dropout有用
缓解过拟合的方法,最直观的想法就是:加权平均,我们建立多个预测模型,将最后的预测值加权平均
上述想法在小的网络、模型中比较有效,但是如果模型非常大,那么就很难计算了
如权重怎么求
怎么生成多个模型?要么模型结构不一样,要么数据集不一样
上述想法的一种逼近方法就是,生成数量为指数阶的模型,将这些模型的预测值求等权重的几何平均,这些模型是共享权重的
dropout就是上面逼近方法的技术
在训练过程中,下面的$l$是第$l$层网络,$\mathbf{y}^{(l)}$是某个样本第$l$ ...