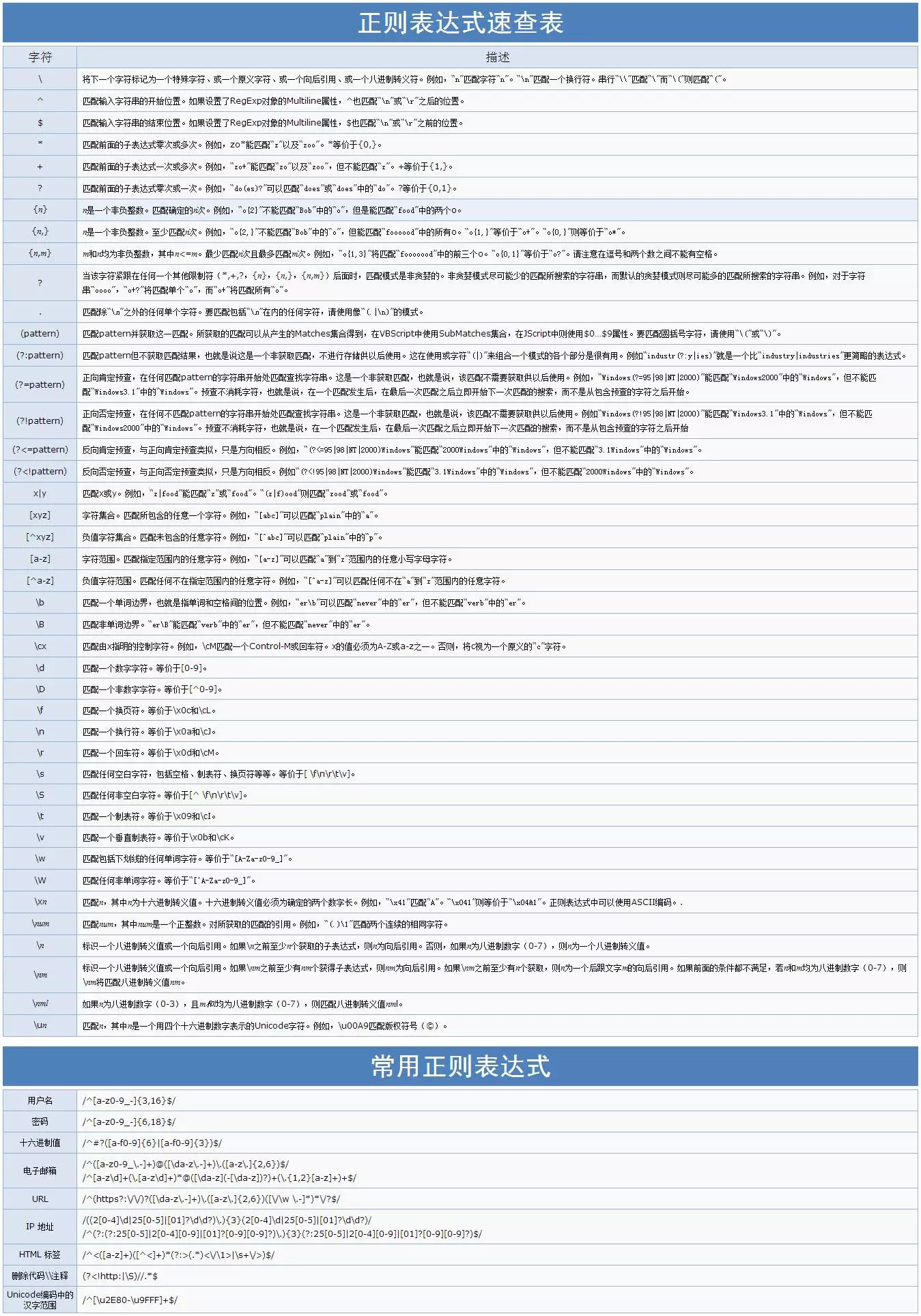
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| str_match
str_match_all
strings <- c(" 219 733 8965", "329-293-8753 ", "banana", "595 794 7569",
"387 287 6718", "apple", "233.398.9187 ", "482 952 3315",
"239 923 8115 and 842 566 4692", "Work: 579-499-7527", "$1000",
"Home: 543.355.3679")
phone <- "([2-9][0-9]{2})[- .]([0-9]{3})[- .]([0-9]{4})"
> str_match(strings, phone)
[,1] [,2] [,3] [,4]
[1,] "219 733 8965" "219" "733" "8965"
[2,] "329-293-8753" "329" "293" "8753"
[3,] NA NA NA NA
[4,] "595 794 7569" "595" "794" "7569"
[5,] "387 287 6718" "387" "287" "6718"
[6,] NA NA NA NA
[7,] "233.398.9187" "233" "398" "9187"
[8,] "482 952 3315" "482" "952" "3315"
[9,] "239 923 8115" "239" "923" "8115"
[10,] "579-499-7527" "579" "499" "7527"
[11,] NA NA NA NA
[12,] "543.355.3679" "543" "355" "3679"
> str_match_all(strings, phone)
[[1]]
[,1] [,2] [,3] [,4]
[1,] "219 733 8965" "219" "733" "8965"
[[2]]
[,1] [,2] [,3] [,4]
[1,] "329-293-8753" "329" "293" "8753"
[[3]]
[,1] [,2] [,3] [,4]
[[4]]
[,1] [,2] [,3] [,4]
[1,] "595 794 7569" "595" "794" "7569"
[[5]]
[,1] [,2] [,3] [,4]
[1,] "387 287 6718" "387" "287" "6718"
[[6]]
[,1] [,2] [,3] [,4]
[[7]]
[,1] [,2] [,3] [,4]
[1,] "233.398.9187" "233" "398" "9187"
[[8]]
[,1] [,2] [,3] [,4]
[1,] "482 952 3315" "482" "952" "3315"
[[9]]
[,1] [,2] [,3] [,4]
[1,] "239 923 8115" "239" "923" "8115"
[2,] "842 566 4692" "842" "566" "4692"
[[10]]
[,1] [,2] [,3] [,4]
[1,] "579-499-7527" "579" "499" "7527"
[[11]]
[,1] [,2] [,3] [,4]
[[12]]
[,1] [,2] [,3] [,4]
[1,] "543.355.3679" "543" "355" "3679"
|