transformer-xl
transformer-xl
- 记录下学习transformer-xl的内容
- 这篇文章主要是在原来的transformer的基础上改进了长度列
- 整个模型的改动就在下面的公式了
- 也就是说,大致改动了两个地方:
- 把上一个encoder的hidden state保存起来,放到当前的计算中去
- 修改了位置变量
第一个改动—->引入cache
- 从文中截取出来的图片;我们在对长文本建模的时候,通常会截断;然后把每个截断的文本丢到模型中去,但是截断的句子,开头的信息是丢失了的,所以就会有信息缺失。
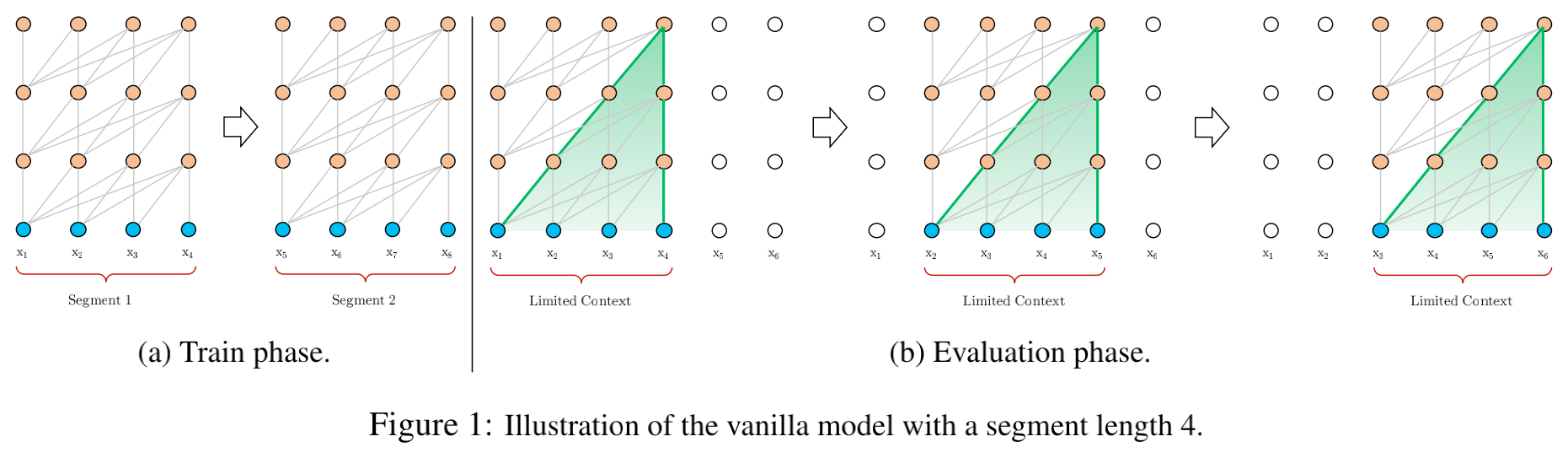
- 原文的做法是把上几个encoder的隐藏状态保存起来,注意这里不会梯度回传。这样做的好处就是,弥补了截断句子开始那几个token的信息。
- 原来在计算k、v的时候,是从当前的hidden state做linear transform得到的
- 现在,hidden state和上一个step的hidden state要拼接在一起,再做linear transform
- 那么,比如每个step的序列长度是12,就会有12个q、k、v
- 加上上一个step的隐藏状态,就会有24个k、v,但是只会有12个q
- 原论文的代码中,是在增加上一个step的
1 | # 原代码长这样,mems就是上一个step的hidden_state,w是当前step,上一层的hidden_state |
第二个改动—->位置信息
- 在加入前一个step的隐藏状态时,会出现一个问题:位置信息会出现重复
- 下面的公式,$h$是隐藏状态,$\tau$是第几个step,$E$是某个token的词向量,$U$是这个token的位置向量
- 也就是说,前一个step的隐藏状态,和现在隐藏状态,相同位置的token,有相同的位置向量
- 也就是,在引入前面的隐藏状态的时候,会导致位置冲突
如何解决位置冲突!!!!
transformers的原论文中,attention的计算方式如下
- 原来的计算方式$EW_{q}^{T}W_{k}E=(E+U)W_{q}^{T}W_{k}(E+U)$
- 把向量中的词向量、位置向量拆分出来
- 本文改成这样子,注意(b),(c),(d)三个部分,就是把$U$全换掉了
- 原论文的代码中是这样写的
1 | # 这个w_head_q就是 上面a中的左边部分, r_w_bias就是c中的u |
- 注意,在原始的transformer里面,位置编码是用sin和embbeding结合的方式,就是:第几个token的位置向量是固定的;但是本文的位置编码不一样
- 改进在下面几点
- 将b中的$U_j$改成$R_{i-j}$,R是sin编码,不需要学习(参数是固定的);这里解决的问题是,两个token的距离用相对的$i-j$来衡量
- 将c中的左边部分改成了$u\in R^{d}$,将d中的左边部分改成了$v \in R^{d}$,原来的是用$U$想乘得到的向量,现在这个是bias,
- 将linear transform的矩阵$W_k$改成$W_{k,R}$和$W_{K,E}$,在原始的attention的结构中,词向量、位置向量都是经过同一个矩阵$W$做的线性变换,现在key的变换不一样了,也就是词向量有一个线性变换、位置向量有一个线性变换,原文的代码如下
1 | r_head_k = self.r_net(r) # R是位置信息变量,第227行 |
- 这里参考博客园的思想:上面的atten得分,每一个项都有各自的含义,
- (a)是词向量去查询词向量,也就完全是内容相关的部分
- (b)是词向量去查询位置信息,是内容的偏置信息
- (c)是位置的偏置去查询词向量,
- (d)是位置的偏置去查询位置信息,
优点
- 文中提到了inductive bias的概念,摘自百度百科:
- 当学习器去预测其未遇到过的输入的结果时,会做一些假设(Mitchell, 1980)。而学习算法中归纳偏置则是这些假设的集合。
- 个人理解:就是模型假设的集合
- 在attention is all you need的论文中,采用了sinusoid函数,好处是这个函数与序列的长度无关,比如在训练集中的句子长度最多是512,新来一个句子,长度是800,那么个sinusoid函数可以很好的表示句子的位置信息
- 本文的位置编码矩阵形式参考了shaw et al.2018,但是shaw的文章用的是可学习的矩阵,本文的矩阵不需要学习